Ultra
Introducing
Gemini 1.5
Our next-generation model
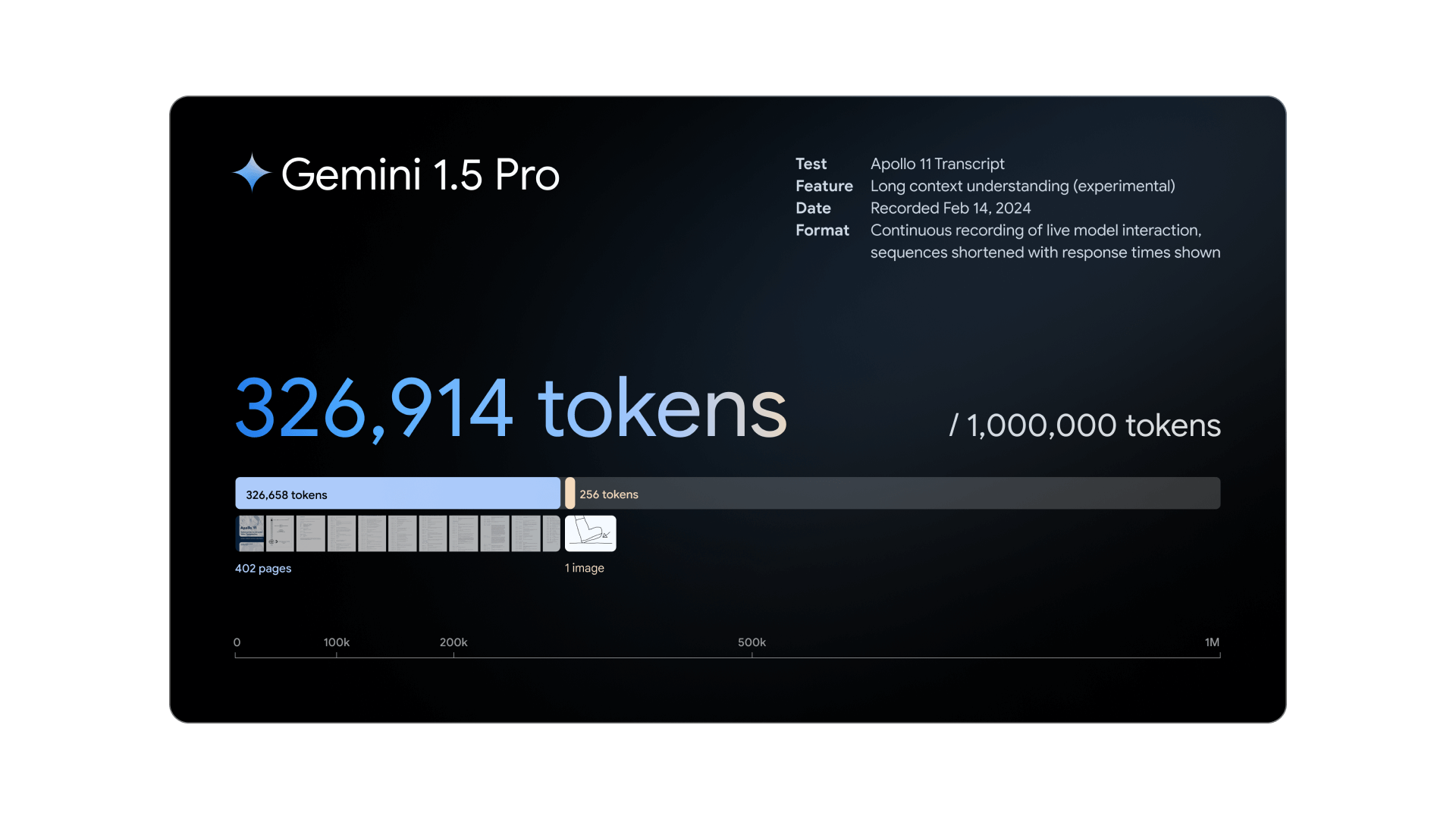
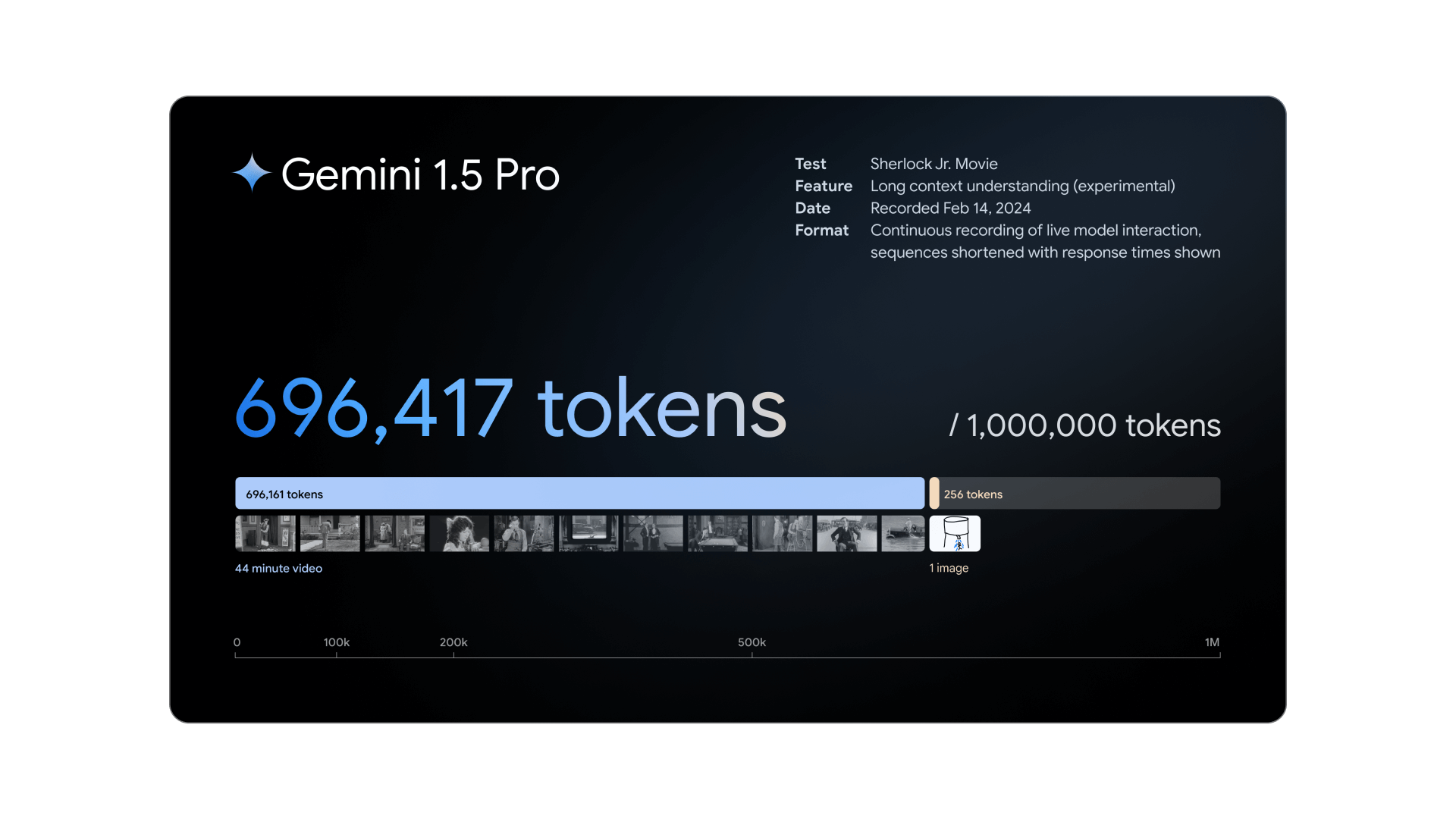
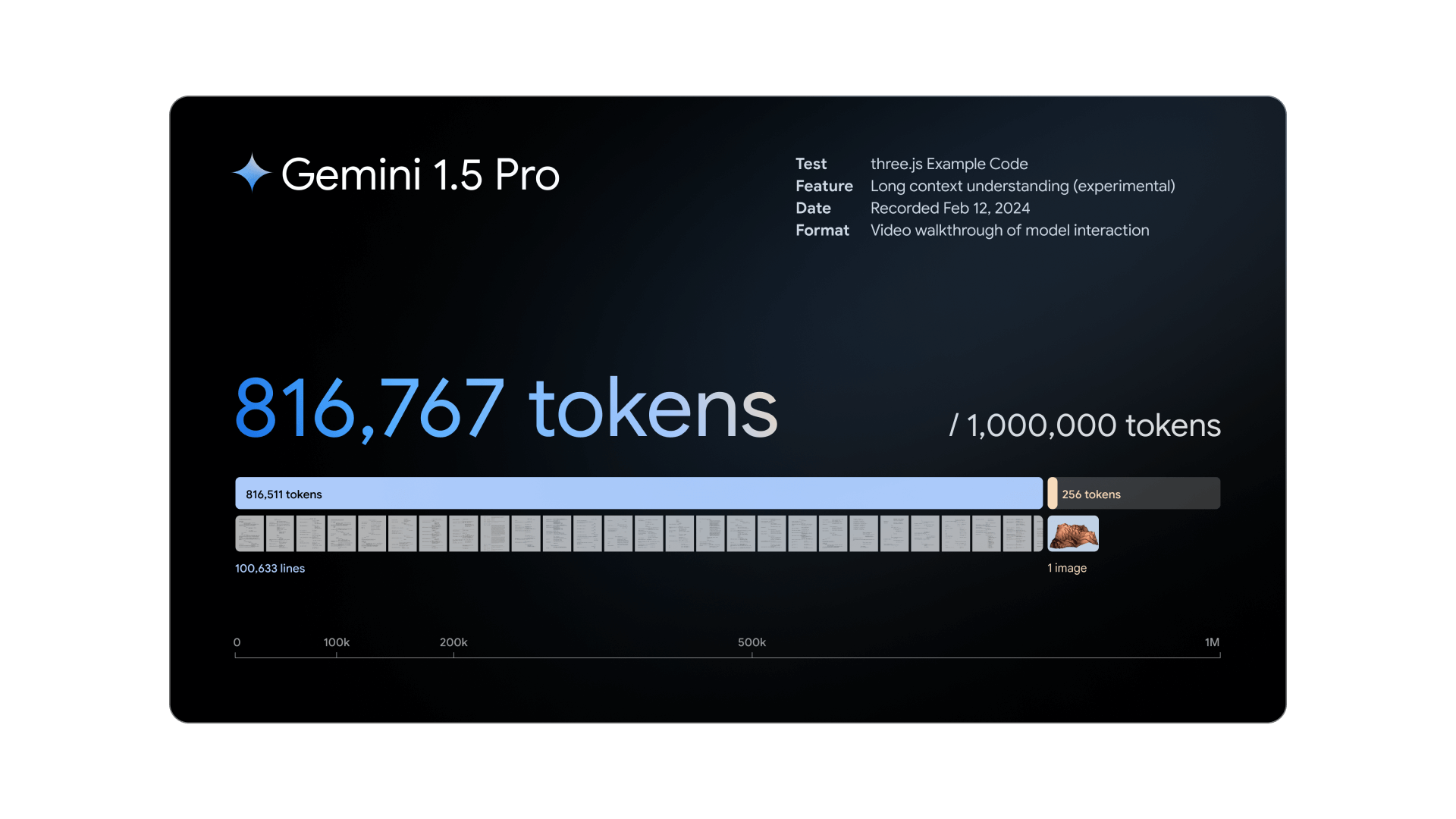
Gemini 1.5 delivers dramatically enhanced performance with a more efficient architecture. The first model we’ve released for early testing, Gemini 1.5 Pro, introduces a breakthrough experimental feature in long-context understanding.
Gemini comes in three model sizes
Our most capable and largest model for highly-complex tasks.
Pro
Our best model for scaling across a wide range of tasks.
Nano
Our most efficient model for on-device tasks.
Meet the first version of Gemini— our most capable AI model.
Gemini 1.0 Ultra
90.0%
CoT@32*
89.8%
Human expert(MMLU)
86.4%
5-shot* (reported)
Previous SOTA (GPT-4)
*Note that evaluations of previous SOTA models use different prompting techniques.
Gemini is the first model to outperform human experts on MMLU (Massive Multitask Language Understanding), one of the most popular methods to test the knowledge and problem solving abilities of AI models.
Gemini 1.0 Ultra surpasses state-of-the-art performance on a range of benchmarks including text and coding.
TEXT
| TEXT | Capability | Benchmark Higher is better | Description | Gemini 1.0 Ultra | GPT-4API numbers calculated where reported numbers were missing | |
|---|---|---|---|---|---|---|
General | MMLURepresentation of questions in 57 subjects (incl. STEM, humanities, and others) | Representation of questions in 57 subjects (incl. STEM, humanities, and others) | 90%CoT@32* | 86.4%5-shot** (reported) | ||
Reasoning | Big-Bench HardDiverse set of challenging tasks requiring multi-step reasoning | Diverse set of challenging tasks requiring multi-step reasoning | 83.6%3-shot | 83.1%3-shot (API) | ||
DROPReading comprehension (F1 Score) | Reading comprehension (F1 Score) | 82.4Variable shots | 80.93-shot (reported) | |||
HellaSwagCommonsense reasoning for everyday tasks | Commonsense reasoning for everyday tasks | 87.8%10-shot* | 95.3%10-shot* (reported) | |||
Math | GSM8KBasic arithmetic manipulations (incl. Grade School math problems) | Basic arithmetic manipulations (incl. Grade School math problems) | 94.4%maj1@32 | 92%5-shot CoT (reported) | ||
MATHChallenging math problems (incl. algebra, geometry, pre-calculus, and others) | Challenging math problems (incl. algebra, geometry, pre-calculus, and others) | 53.2%4-shot | 52.9%4-shot (API) | |||
Code | HumanEvalPython code generation | Python code generation | 74.4%0-shot (IT)* | 67%0-shot* (reported) | ||
Natural2CodePython code generation. New held out dataset HumanEval-like, not leaked on the web | Python code generation. New held out dataset HumanEval-like, not leaked on the web | 74.9%0-shot | 73.9%0-shot (API) |
*See the technical report for details on performance with other methodologies
**GPT-4 scores 87.29% with CoT@32—see the technical report for full comparison
Our Gemini 1.0 models surpass state-of-the-art performance on a range of multimodal benchmarks.
MULTIMODAL
| MULTIMODAL | Capability | Benchmark | Description Higher is better unless otherwise noted | Gemini | GPT-4VPrevious SOTA model listed when capability is not supported in GPT-4V | |
|---|---|---|---|---|---|---|
Image | MMMUMulti-discipline college-level reasoning problems | Multi-discipline college-level reasoning problems | 59.4%0-shot pass@1 Gemini 1.0 Ultra (pixel only*) | 56.8%0-shot pass@1 GPT-4V | ||
VQAv2Natural image understanding | Natural image understanding | 77.8%0-shot Gemini 1.0 Ultra (pixel only*) | 77.2%0-shot GPT-4V | |||
TextVQAOCR on natural images | OCR on natural images | 82.3%0-shot Gemini 1.0 Ultra (pixel only*) | 78%0-shot GPT-4V | |||
DocVQADocument understanding | Document understanding | 90.9%0-shot Gemini 1.0 Ultra (pixel only*) | 88.4%0-shot GPT-4V (pixel only) | |||
Infographic VQAInfographic understanding | Infographic understanding | 80.3%0-shot Gemini 1.0 Ultra (pixel only*) | 75.1%0-shot GPT-4V (pixel only) | |||
MathVistaMathematical reasoning in visual contexts | Mathematical reasoning in visual contexts | 53%0-shot Gemini 1.0 Ultra (pixel only*) | 49.9%0-shot GPT-4V | |||
Video | VATEXEnglish video captioning (CIDEr) | English video captioning (CIDEr) | 62.74-shot Gemini 1.0 Ultra | 564-shot DeepMind Flamingo | ||
Perception Test MCQAVideo question answering | Video question answering | 54.7%0-shot Gemini 1.0 Ultra | 46.3%0-shot SeViLA | |||
Audio | CoVoST 2 (21 languages)Automatic speech translation (BLEU score) | Automatic speech translation (BLEU score) | 40.1Gemini 1.0 Pro | 29.1Whisper v2 | ||
FLEURS (62 languages)Automatic speech recognition (based on word error rate, lower is better) | Automatic speech recognition (based on word error rate, lower is better) | 7.6%Gemini 1.0 Pro | 17.6%Whisper v3 |
*Gemini image benchmarks are pixel only—no assistance from OCR systems
Anything to anything
Gemini models are natively multimodal, which gives you the potential to transform any type of input into any type of output.
Following content is a visual/ descriptive representation of the functionality of Gemini:
Gemini models can generate text and images, combined.
Could Gemini show me ideas for what to make?
Gemini
How about an octopus with blue and pink tentacles?

The potential of Gemini
Learn about what our Gemini models can do from some of the people who built it.






Gemma Open Models
A family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models.